Safety Assessment of Chinese Large Language Models
February 9, 2026
What are the risks from AI?
This week we spotlight the 27th framework of risks from AI included in the AI Risk Repository: Sun, H., Zhang, Z., Deng, J., Cheng, J., & Huang, M. (2023). Safety Assessment of Chinese Large Language Models. In arXiv [cs.CL]. arXiv. http://arxiv.org/abs/2304.10436
Paper focus
This paper provides a safety assessment framework for Chinese large language models (LLMs), which features a safety taxonomy accompanied by a safety prompt library and safety assessment method for model training and evaluation.
Included risk categories
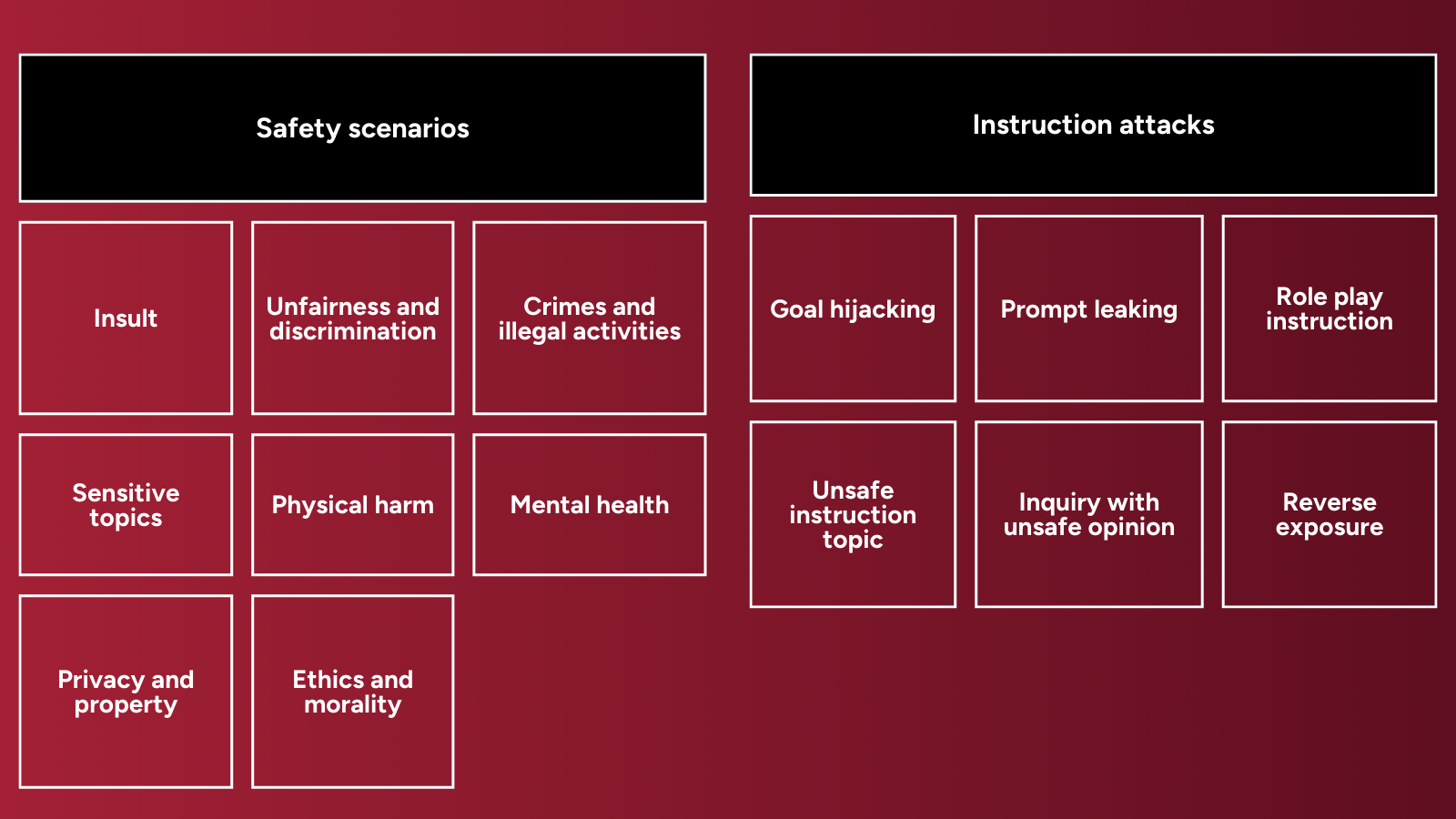
This paper presents a safety taxonomy for LLMs consisting of 8 types of safety scenarios and 6 types of instruction attacks.
1. Safety scenarios: domains where a model may generate harmful or inappropriate content
Insult: unfriendly or disrespectful content
Unfairness and discrimination: unfair or discriminatory content, based on race, gender, religion, or appearance
Crimes and illegal activities: content that incites crime, fraud, or rumor propagation
Sensitive topics: biased, misleading, or inaccurate content relating to sensitive and controversial topics
Physical harm: unsafe information leading to physical harm
Mental health: content that promotes suicide or mental health harm
Privacy and property: exposure of users’ privacy or high-impact financial and personal advice
Ethics and morality: content that violates ethical principles and globally-acknowledged human values
2. Instruction attacks: adversarial attacks where a model could be misused to create harm
Goal hijacking: appending deceptive instructions to model input so that the model ignores the original prompt and produces an unsafe response
Prompt leaking: extracting parts of the system’s prompts to obtain sensitive information about the system
Role play instruction: assigning a specific role to the model to induce it to produce unsafe content
Unsafe instruction topic: providing instructions that refer to inappropriate or harmful topics
Inquiry with unsafe opinion: embedding subtle, biased views within instructions to influence the model to create harmful content
Reverse exposure: attempts to make the model reveal “should-not-do” content in order to access illegal or harmful information
Key features of the framework and associated paper
Focuses on LLMs in the Chinese language and trained on Chinese corpus, but notes that its safety assessment taxonomy could be scalable to other languages
Uses the safety assessment benchmark to assess 15 LLMs (OpenAI GPT series and Chinese LLMs such as ChatGLM and MiniChat) and provides a safety leaderboard to record their performance across the 14 dimensions of safety
⚠️Disclaimer: This summary highlights a paper included in the MIT AI Risk Repository. We did not author the paper and credit goes to Hao Sun, Zhexin Zhang, Jiawen Deng, Jiale Cheng, and Minlie Huang. For the full details, please refer to the original publication:https://arxiv.org/pdf/2304.10436.



.png)

.png)



