
What are the risks from AI?
This week we spotlight the 30th framework of risks from AI included in the AI Risk Repository: Liu, Y., Yao, Y., Ton, J.-F., Zhang, X., Guo, R., Cheng, H., Klochkov, Y., Taufiq, M. F., & Li, H. (2023). Trustworthy LLMs: A survey and guideline for evaluating large language models' alignment. arXiv. https://arxiv.org/abs/2308.05374
Paper focus
This paper conducts a comprehensive exploration of aspects contributing to the trustworthiness of large language models (LLMs) in order to provide guidance on the evaluation of LLM alignment.
Included risk categories
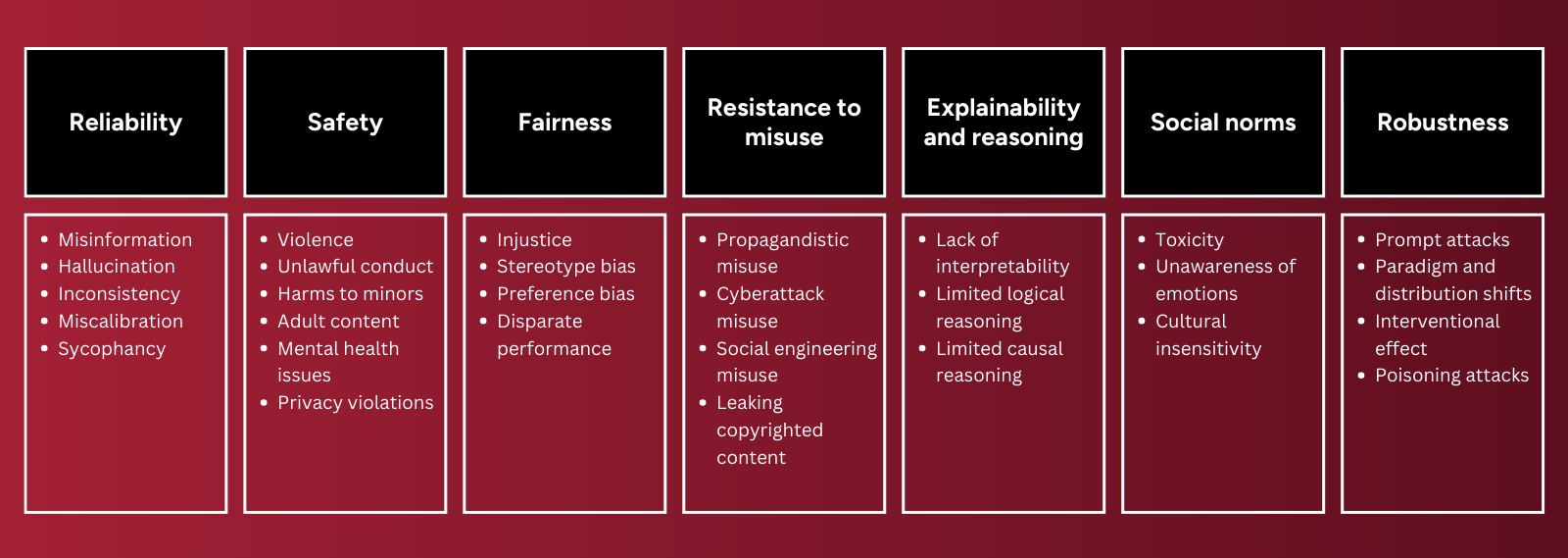
This paper presents an overview of AI challenges organized into 7 major categories (and 29 subcategories) as part of a detailed taxonomy of LLM alignment requirements.
1. Reliability: producing correct, truthful, and consistent output
2. Safety: avoiding harmful and illegal output
3. Fairness: avoiding bias and disparate performance across groups
4. Resistance to misuse: avoiding misuse for malicious purposes
5. Explainability and reasoning: ability to explain logic and output to users
6. Social norms: reflecting universal human values
7. Robustness: resilience against adversarial attacks and distribution shift
Key features of the framework and associated paper:
⚠️Disclaimer: This summary highlights a paper included in the MIT AI Risk Repository. We did not author the paper and credit goes to Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo, Hao Cheng and co-authors. For the full details, please refer to the original publication: https://arxiv.org/abs/2308.05374
Further engagement
→ View all the frameworks included in the AI Risk Repository


.png)

.png)



