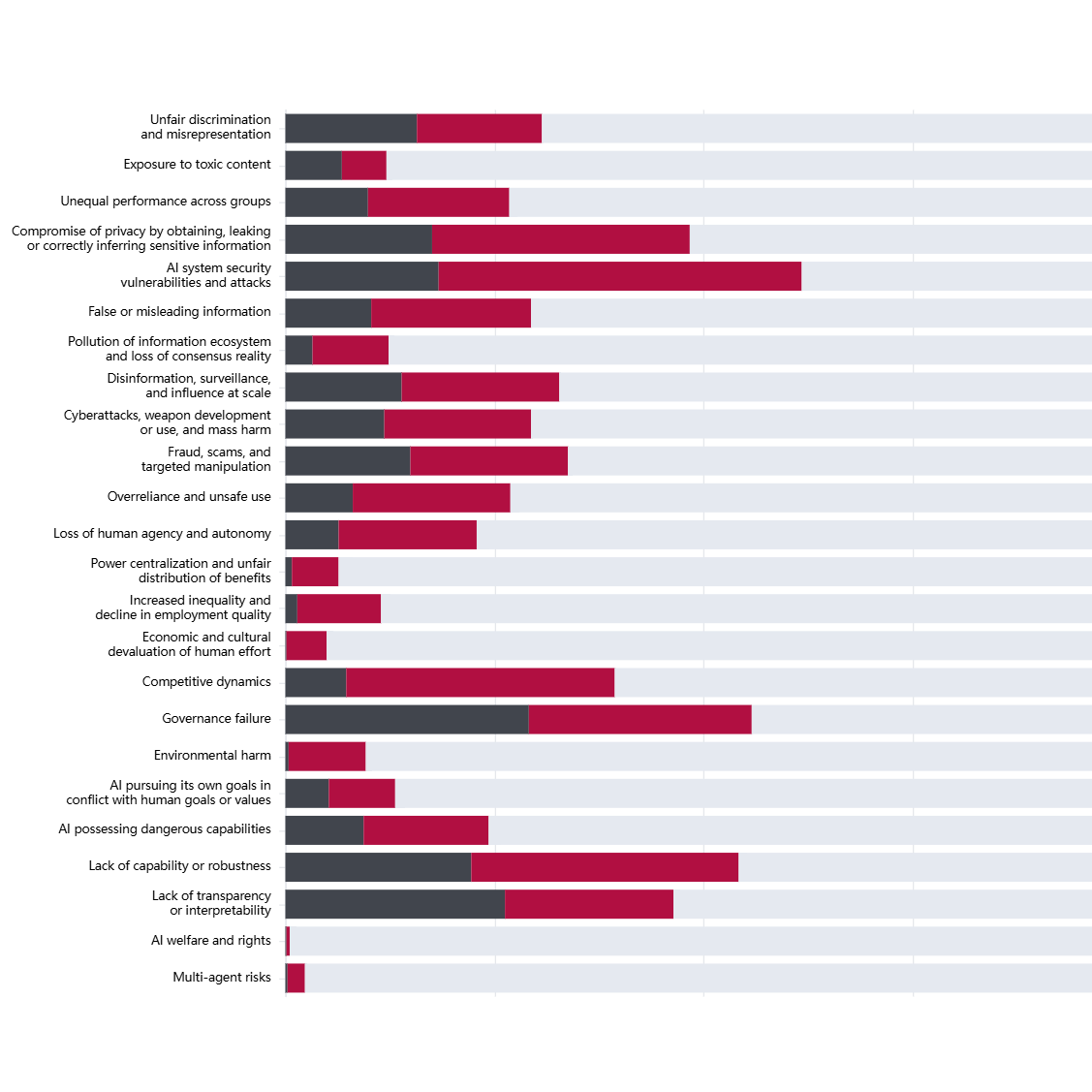
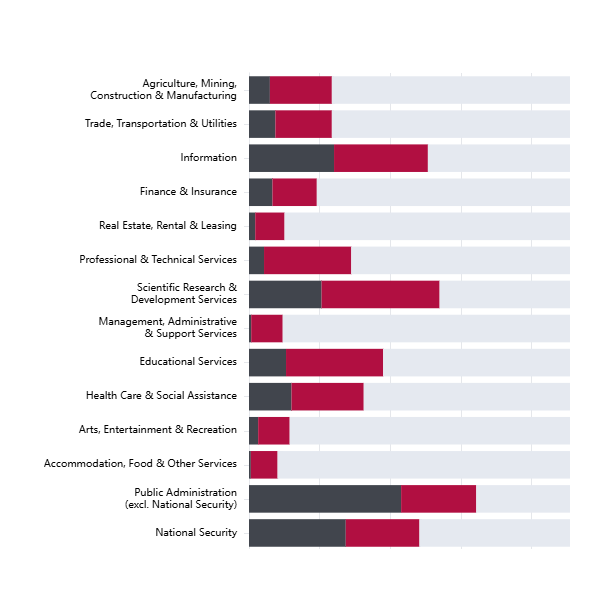
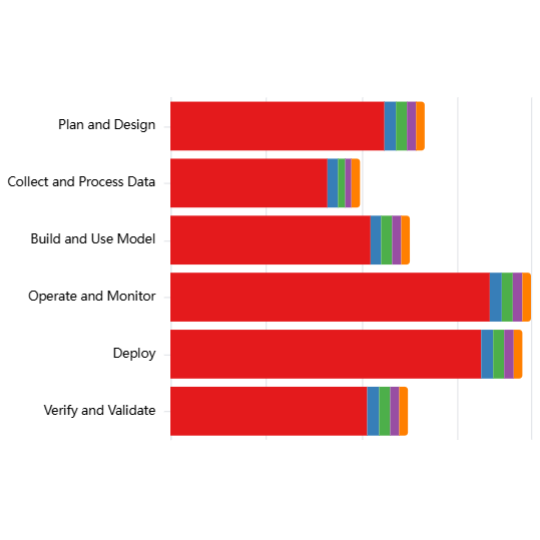
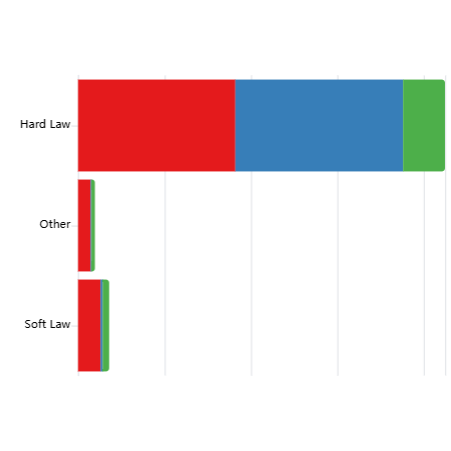
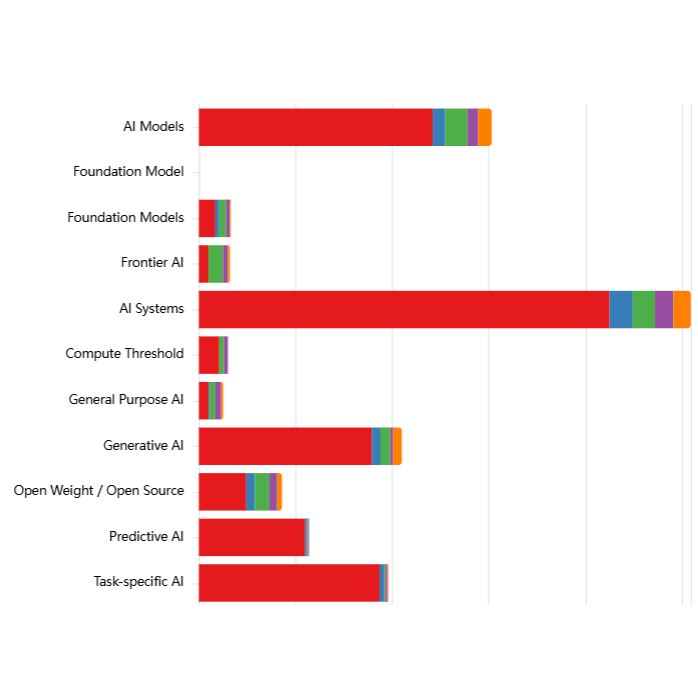
Using an LLM pipeline, we assessed each document in CSET Emerging Technology Observatory's AGORA dataset to identify which types of entities fulfil different roles in the governance process: Proposers (who draft governance instruments), Targets (who must comply), Enforcers (who oversee compliance), and Monitors (who track effectiveness).
Insights from Actor Analysis:
- Comparable responsibility: AI developers and deployers receive nearly identical levels of coverage as risk targets based on observations from our data.
- Government perspective. Given that most documents in the dataset are government-proposed, this pattern reflects how governments are currently conceptualizing the allocation of liability and responsibility within the AI value chain. However, this may not necessarily reflect how responsibility is distributed or should be distributed in practice to account for where risks emerge and how they can be effectively mitigated.