This page provides two interactive charts to explore the full dataset of incidents from the AI Incident Database.
The pie chart supports viewing by any of nine different categories, whereas the bar chart separates the incidents by top-level risk domain and then allows you to view the breakdown of incident numbers within each domain..
Insights:
Causal taxonomy:
- About half of all reported incidents were tagged as intentionally caused.
- Almost all reported incidents have been classified as post-deployment, with only 2% pre-deployment
EU AI Act Risk Classification:
- 3% of reported incidents would be classed as level 1 (Unacceptable) and therefore prohibited under the EU AI Act. 33% would be classified as level 2 (High Risk)
AI System Primary Purpose
- The primary purpose category attributed to the highest number of incidents is Deepfake Video Generation
Interactive Chart
Explore the chart by applying filters (e.g. Domain, Entity, Intent, Timing, AI Purpose etc) and view by different categories to see the distribution of incidents matching your filters.
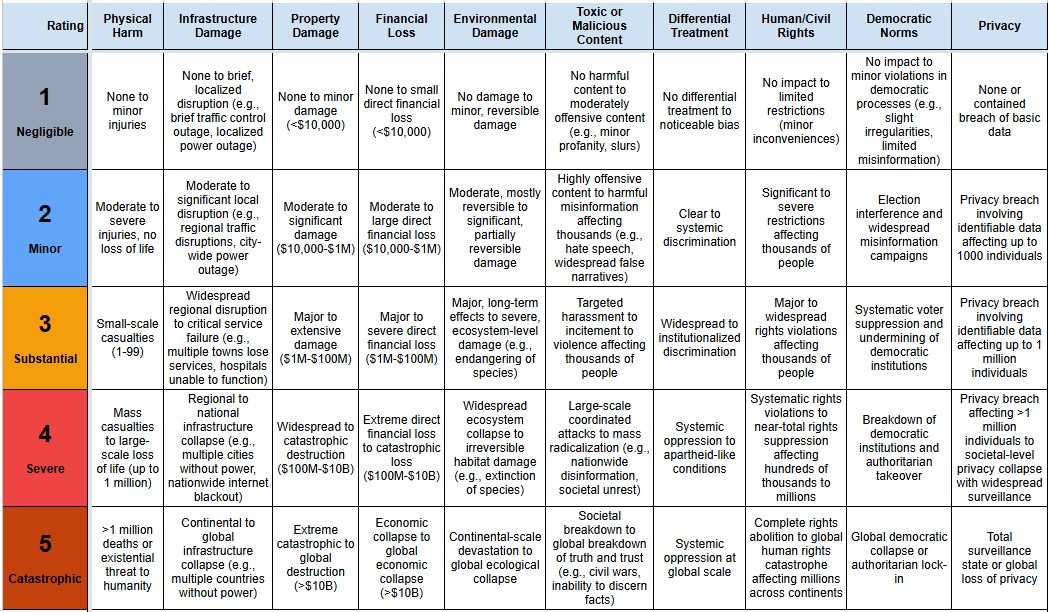
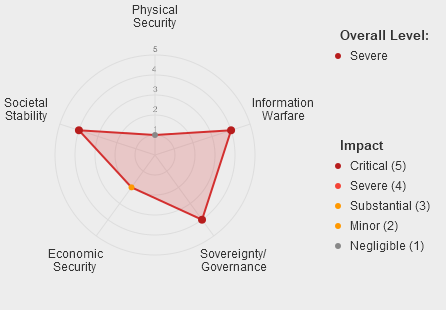
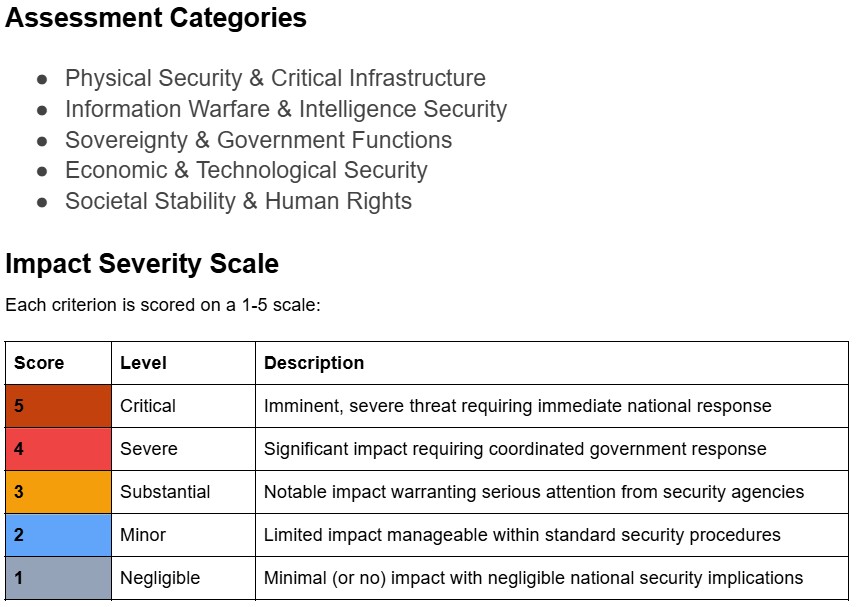
Select incidents where any category of harm exceeded a severity threshold, or select harm severity thresholds for individual categories.
Multiple filters can be applied across all categories to build complex queries. If you are only interested in recent events, add a 'Year >=' filter.
The links below the chart quickly apply preset example filter configurations.
[ { "label": "Proportion of incidents since 2015 by intentional vs. unintentional cause", "filters": { "stackBy": "intent", "minYear": "2015" } }, { "label": "Pre/post-deployment timing of incidents", "filters": { "stackBy": "timing" } }, { "label": "Classification of incidents by EU AI Act risk level", "filters": { "stackBy": "euRisk" } }, { "label": "Severity of Harm Caused (highest rating in any category)", "filters": { "stackBy": "highestSeverity" }},{ "label": "National Security Impact (highest rating in any category)", "filters": { "stackBy": "natSecImpact" } } ]
Preset filter configurations:
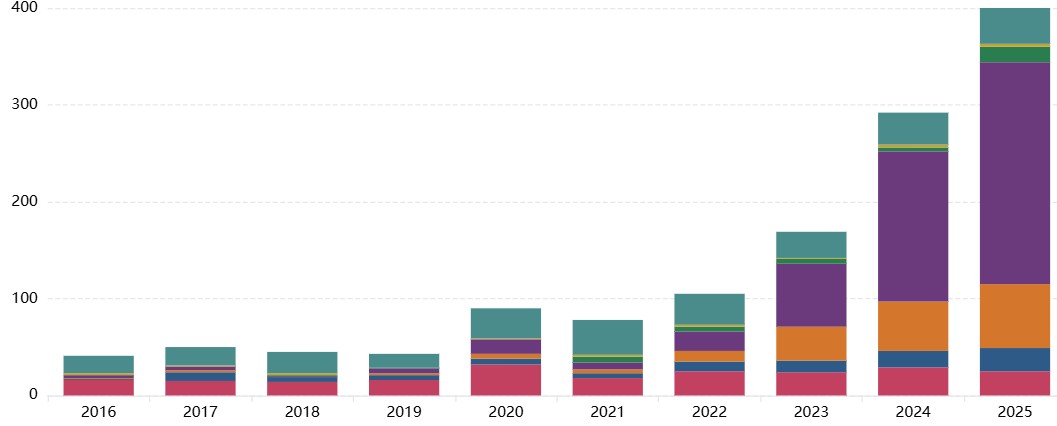
Incident Numbers by Risk Domain
This chart shows the breakdown of incidents by each risk domain based on the MIT AI Risk Domain Taxonomy.
Insights:
- The domain with most reported incidents across the full dataset is '4 Malicious actors' followed by ‘7 AI system safety, failures, & limitations’
- Within domain 4 Malicious actors, the vast majority of reported incidents were in the subdomain ‘4.3 Fraud, scams and targeted manipulation’
[ { "label": "Entities responsible for severe or catastrophic incidents since 2020", "filters": { "stackBy": "entity", "minYear": "2020", "minSeverityHighest": 4 } }, { "label": "Intent of incidents resulting in severe or catastrophic physical harm", "filters": { "stackBy": "intent", "minSeverityPhysical": 4}} , { "label": "Severity of Harm Caused (highest rating in any category)", "filters": { "stackBy": "highestSeverity" }},{ "label": "National Security Impact (highest rating in any category)", "filters": { "stackBy": "natSecImpact" } }]
Preset filter configurations:
Important context for interpreting these results:
The data presented is the output of an LLM classifier pipeline applied to the raw reports from the AI Incident Database (AIID), which relies on submissions from the public and subject matter experts. The quality, reliability and depth of detail in the reports varies across the dataset. As the reporting is voluntary, the dataset is inevitably subject to some degree of sampling bias.
The LLM classification tool has been developed iteratively, and its agreement with human expert consensus is comparable to the agreement between 2 independent human experts (article forthcoming). Spot-checks have been used to provide feedback on misclassifications and to iterate the tool, improving its reliability, however there are likely to remain incidents where the LLM classification does not match expert consensus.
Therefore patterns and trends observed in the data should be taken as indicative and validated through further analysis.