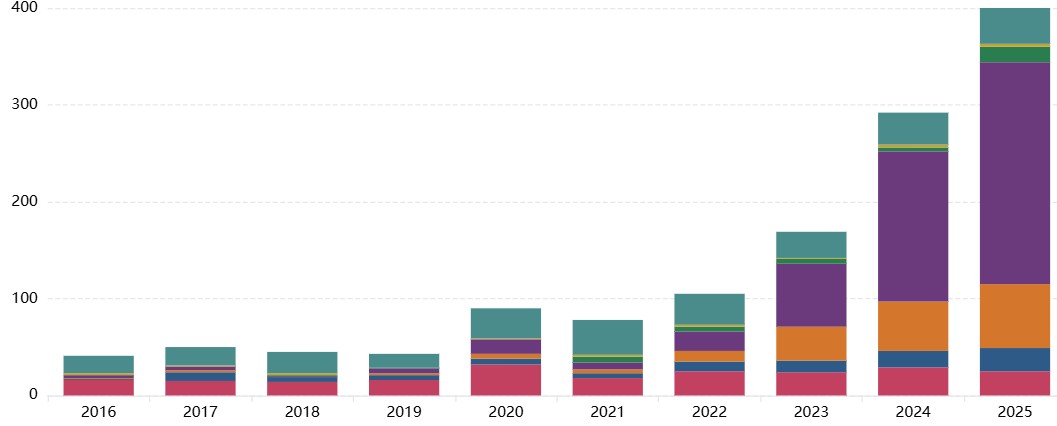
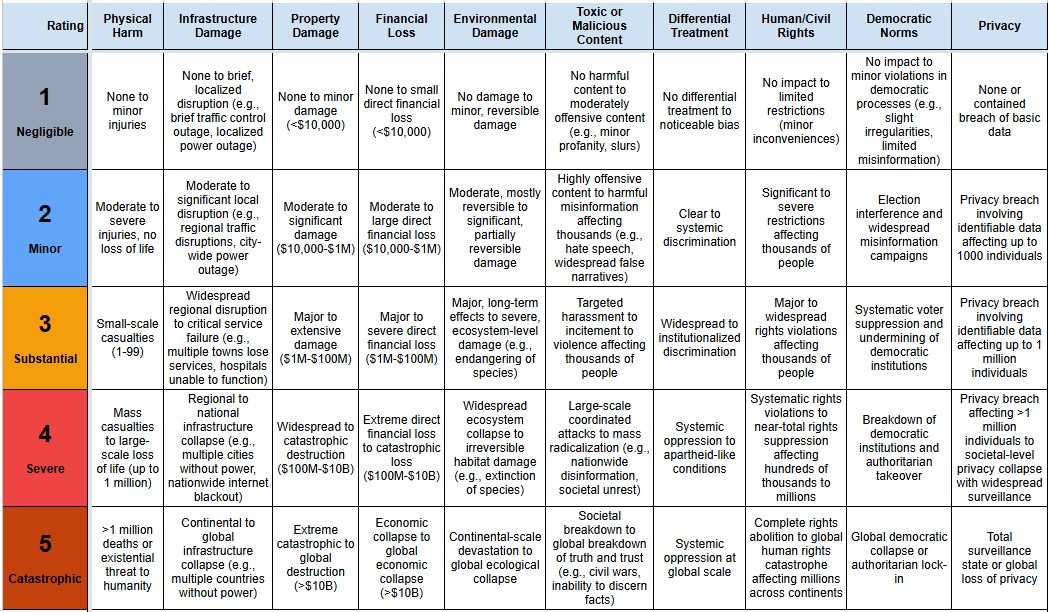
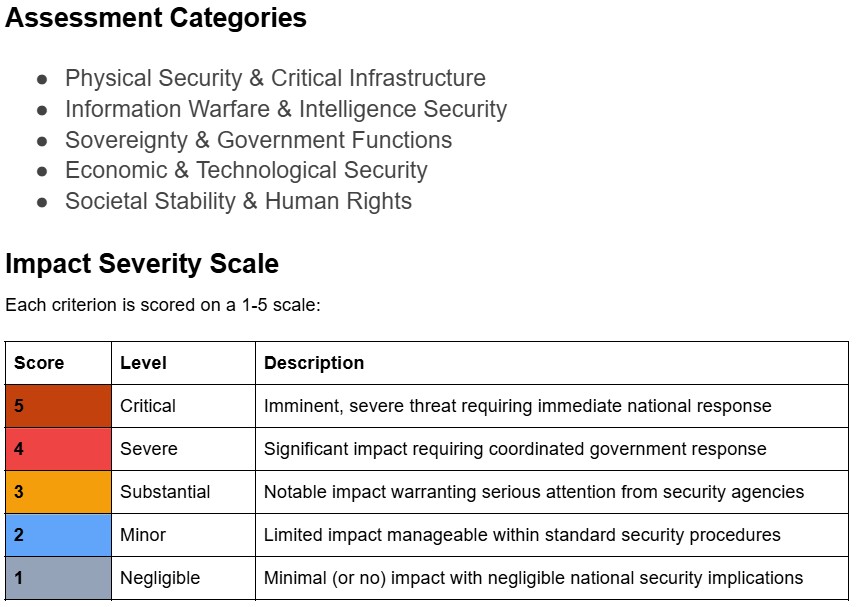
View detailed assessments of the National Security impact of each incident in the AI Incident Database, including 5 categories of impact and threat classification (novelty, imminence, autonomy) based on this National Security Impact Framework.
Complex queries can be built by adding filters across multiple categories.
[ { "label": "Incidents associated with fully autonomous AI systems", "filters": { "natSecAutonomy": "Full autonomy" } }, { "label": "Near-term and Immediate imminence with Overall Severe or Catastrophic", "filters": { "natSecImminence": ["Near-term", "Immediate"], "minNatSecOverall": "4" } }, { "label": "First-of-its-kind incidents", "filters": { "natSecNovelty": "First-of-its-kind" } } ]
Preset filter configurations:
Important context for interpreting these results:
The data presented is the output of an LLM classifier pipeline applied to the raw reports from the AI Incident Database (AIID), which relies on submissions from the public and subject matter experts. The quality, reliability and depth of detail in the reports varies across the dataset. As the reporting is voluntary, the dataset is inevitably subject to some degree of sampling bias.
The LLM classification tool has been developed iteratively, and its agreement with human expert consensus is comparable to the agreement between 2 independent human experts (article forthcoming). Spot-checks have been used to provide feedback on misclassifications and to iterate the tool, improving its reliability, however there are likely to remain incidents where the LLM classification does not match expert consensus.
Therefore patterns and trends observed in the data should be taken as indicative and validated through further analysis.